Computer organization and architecture miscellaneous
- Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction (DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are 5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of each buffer is 1 ns. A program consisting of 12 instructions I1, I2, I3,..., I12 is executed in this pipelined processor. Instruction I4 is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, the time (in ns) needed to complete the program is
-
View Hint View Answer Discuss in Forum
Instruction pipeline with five stages without any branch predicition : Delays for FI, DI, FO.EI and WO are 5,7,10,8,6 ns respectively. The maximum time taken by any stage is 10 ns and additional 1ns is required for delay of buffer.
∴ The total time for an instruction to pass from one stage to another in 11 ns.
The instructions are executed in the following order l1, l2, l3 , l4 , l9 , l10, l11, l12
Execution with Time
Now when l4 is in its execution stage we detect the branch and when l4 is in WO stage we fetch I9 so time for execution of instructions from l9 to l12 is = 11* 5 +(4 – 1) * 11= 88 ns.
But we save 11 ns when fetching l9 i.e., l9 requires only 44 ns additional instead of 55 ns because time for fetching l9 can be overlap with WO of l4.
∴ Total Time is = 88 + 88 – 11 = 165 nsCorrect Option: B
Instruction pipeline with five stages without any branch predicition : Delays for FI, DI, FO.EI and WO are 5,7,10,8,6 ns respectively. The maximum time taken by any stage is 10 ns and additional 1ns is required for delay of buffer.
∴ The total time for an instruction to pass from one stage to another in 11 ns.
The instructions are executed in the following order l1, l2, l3 , l4 , l9 , l10, l11, l12
Execution with Time
Now when l4 is in its execution stage we detect the branch and when l4 is in WO stage we fetch I9 so time for execution of instructions from l9 to l12 is = 11* 5 +(4 – 1) * 11= 88 ns.
But we save 11 ns when fetching l9 i.e., l9 requires only 44 ns additional instead of 55 ns because time for fetching l9 can be overlap with WO of l4.
∴ Total Time is = 88 + 88 – 11 = 165 ns
- Consider the following processors (ns stands for nanoseconds). Assume that the pipeline registers have zero latency. P1 : Four-stage pipeline with stage latencies 1 ns, 2 ns, 2 ns, 1 ns.
P2 : Four-stage pipeline with stage latencies 1 ns, 1.5 ns, 1.5 ns, 1.5 ns.
P3 : Five-stage pipeline with stage latencies 0.5 ns, 1 ns, 1 ns, 0.6 ns, 1 ns.
P4 : Five-stage pipeline with stage latencies 0.5 ns, 0.5 ns, 1 ns, 1 ns, 1.1 ns.
Which processor has the highest peak clock frequency ?
-
View Hint View Answer Discuss in Forum
Frequency ∝ 1 clock period
Clock period = maximum stage delay + overhead
P1 : CP = Max (1, 2, 2, 1) = 2 ns
P2 : CP = Max (1, 1.5, 1.5, 1.5) = 1.5 ns
P3 : CP = Max (0.5, 1, 1, 0.6, 1) = 1 ns
P4 : CP = Max (0.5, 0.5, 1, 1, 1, 1) = 1.1 ns
∵ CP of P3 is less, it has highest frequencyFrequency 1 P3 = 1 = 1 GHz 1 ns Correct Option: C
Frequency ∝ 1 clock period
Clock period = maximum stage delay + overhead
P1 : CP = Max (1, 2, 2, 1) = 2 ns
P2 : CP = Max (1, 1.5, 1.5, 1.5) = 1.5 ns
P3 : CP = Max (0.5, 1, 1, 0.6, 1) = 1 ns
P4 : CP = Max (0.5, 0.5, 1, 1, 1, 1) = 1.1 ns
∵ CP of P3 is less, it has highest frequencyFrequency 1 P3 = 1 = 1 GHz 1 ns
- An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the EX stage and produce the next instruction pointer at the end of the EX stage in the old design and at the end of the EX2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is __________.
-
View Hint View Answer Discuss in Forum
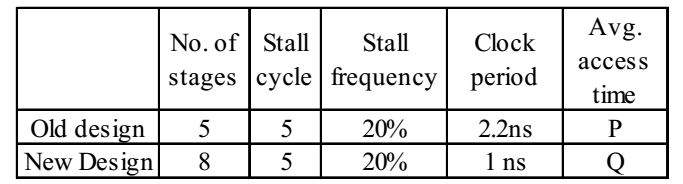
P = 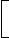
80% (1 clock) + 20% 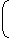
1
completion+ 2
stack clock
× Tc -p
P = (0.8 + 0.6) × 2.2 ns = 3.08 nsQ = 80% (1 clock) + 20% 1
completion+ 5
stack clock× Tc -p
P = (0.8 + 0.12) × 1 ns = 2 nsSo the value of P = 3.08 ns = 1.54 Q 2 ns Correct Option: A
P = 80% (1 clock) + 20% 1
completion+ 2
stack clock× Tc -p
P = (0.8 + 0.6) × 2.2 ns = 3.08 nsQ = 80% (1 clock) + 20% 1
completion+ 5
stack clock× Tc -p
P = (0.8 + 0.12) × 1 ns = 2 nsSo the value of P = 3.08 ns = 1.54 Q 2 ns
- Consider a 6-stage instruction pipeline, where all stages are perfectly balanced. Assume that there is no cycle-time overhead of pipelining. When an application is executing on this 6-stage pipeline, the speedup achieved with respect to non-pipelined execution if 25% of the instructions incur 2 pipeline stall cycles is ______________________.
-
View Hint View Answer Discuss in Forum
4 to 4
Correct Option: B
4 to 4
- Consider the following reservation table for a pipeline having three stages S1, S2, and S3.
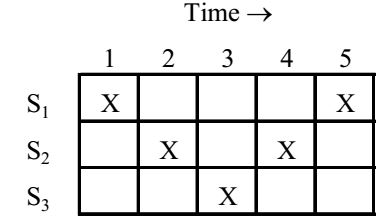
The Minimum Average Latency (MAL) is _____.
-
View Hint View Answer Discuss in Forum
NA
Correct Option: D
NA

