Computer organization and architecture miscellaneous
- In a two-level cache system, the access times of L1 and L2 caches are 1 and 8 clock cycles, respectively. The miss penalty from the L2 cache to main memory is 18 clock cycles. The miss rate of L1 cache is twice that of L2. The average memory access time (AMAT) of this cache system is 2 cycles. The miss rates of L1 and L2 respectively are :
-
View Hint View Answer Discuss in Forum
As given that :
The access time L1 = 1 clock cycles
or (Hit time)
The access time L2 = 8 clock cycles
or (Hit time)
Miss penality L2 = 18 clock cycles
(TAvg = 2 cycles)
Miss Rate (L1 = 2X)
Miss Rate (L2 = X)
As we know that,
TAverage = Hit time L1 + (Miss Rate L1 × Miss Palenality L1) ...(1)
Miss Palenality L1 = Hit time L2 + (Miss Rate L2 × Miss Palenality L2) ....(2)
Put the given values in equation (1) and (2).
2 = 1 + 2 × (Miss Palenality 4)
1 = 2 × (L1)X = 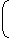
1 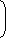
.....(3) 2L1
(Miss Palenality L1) = 8 + X. (18)
From eq. (3) put (L1) value to eq. (4)L1 = 1 2X 1 = 8 + 18X 2X 1 - 18X = 8 2X
1 - 36X2 = 16X
36X2 + 16X - 1 = 0
Compare to aX2 + bX + c = 0
a = 36, b = 16, c = –1= - b ± √b² - 4ac 2a = -16 ± √256 + 4 × 36 × 1 2 × 36 = -16 ± 2 = 4 (take +ve value only) 72 72 X = 0.055
Then Miss rate L1 = 2X = 2 × 0.055 = 0.111
L2 = X = 0.055
Hence option (a) is correct.
Correct Option: A
As given that :
The access time L1 = 1 clock cycles
or (Hit time)
The access time L2 = 8 clock cycles
or (Hit time)
Miss penality L2 = 18 clock cycles
(TAvg = 2 cycles)
Miss Rate (L1 = 2X)
Miss Rate (L2 = X)
As we know that,
TAverage = Hit time L1 + (Miss Rate L1 × Miss Palenality L1) ...(1)
Miss Palenality L1 = Hit time L2 + (Miss Rate L2 × Miss Palenality L2) ....(2)
Put the given values in equation (1) and (2).
2 = 1 + 2 × (Miss Palenality 4)
1 = 2 × (L1)X = 1 .....(3) 2L1
(Miss Palenality L1) = 8 + X. (18)
From eq. (3) put (L1) value to eq. (4)L1 = 1 2X 1 = 8 + 18X 2X 1 - 18X = 8 2X
1 - 36X2 = 16X
36X2 + 16X - 1 = 0
Compare to aX2 + bX + c = 0
a = 36, b = 16, c = –1= - b ± √b² - 4ac 2a = -16 ± √256 + 4 × 36 × 1 2 × 36 = -16 ± 2 = 4 (take +ve value only) 72 72 X = 0.055
Then Miss rate L1 = 2X = 2 × 0.055 = 0.111
L2 = X = 0.055
Hence option (a) is correct.
- A cache memory unit with capacity of N words and block size of B words is to be designed. If it is designed as a direct mapped cache, the length of the TAG field is 10 bits. If the cache unit is now designed as a 16-way set-associative cache, the length of the TAG field is______ bits.
-
View Hint View Answer Discuss in Forum
In Direct Mapped :

No. of line in direct mapped cache = 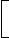
N 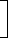
bits B For No. of line = log N B
In Set Associative :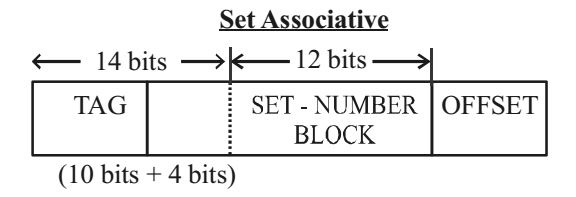
TAG1 + log N + log(B) = TAG2 + log N + log(B) B 16 B
By cancelling the same terms
As given that
TAG1 = 10 bits for Direct Mapping.
TAG2 let say X bits.Then , 10 + log N = X + log N B 16 B
By taking exponentation both side w.r.t 2.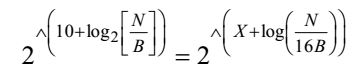
(2^10)* N = (2^X)* N B 16 B (2^10) = (2^X) 1 16 (2^10) = (2^X) 1 2^4
(2^14) = (2^X)X = 14
So, the required length of TAG field in Set Associative mapped is = 14.
Correct Option: C
In Direct Mapped :
No. of line in direct mapped cache = N bits B For No. of line = log N B
In Set Associative :TAG1 + log N + log(B) = TAG2 + log N + log(B) B 16 B
By cancelling the same terms
As given that
TAG1 = 10 bits for Direct Mapping.
TAG2 let say X bits.Then , 10 + log N = X + log N B 16 B
By taking exponentation both side w.r.t 2.(2^10)* N = (2^X)* N B 16 B (2^10) = (2^X) 1 16 (2^10) = (2^X) 1 2^4
(2^14) = (2^X)X = 14
So, the required length of TAG field in Set Associative mapped is = 14.
- Consider a two-level cache hierarchy with LI and L2 caches. An application incurs 1.4 memory accesses per instruction on average. For this application, the miss rate of L1 cache is 0.1; the L2 cache experiences, on average. 7 misses per 1000 instructions. The miss rate of L2 expressed correct to two decimal places is________.
-
View Hint View Answer Discuss in Forum
As given that, an application incurs 1.4 memory accesses per instruction.
So, the Number of memory Accesses in 1000 instructions is
= 1.4 × 1000 = 1400.
Number of Misses in L2 cache= Miss per instructions Number of Memory Accesses = 7 Miss (Per 1000 instruction) = 0.005 1400 (Memory Accesses) Miss rate L2 = Miss in L2 Miss in L1
∴ (given, Miss rate of L1 cache is 0.1)So , L2 = 0.005 0.1
Miss in L2 = 0.05Correct Option: A
As given that, an application incurs 1.4 memory accesses per instruction.
So, the Number of memory Accesses in 1000 instructions is
= 1.4 × 1000 = 1400.
Number of Misses in L2 cache= Miss per instructions Number of Memory Accesses = 7 Miss (Per 1000 instruction) = 0.005 1400 (Memory Accesses) Miss rate L2 = Miss in L2 Miss in L1
∴ (given, Miss rate of L1 cache is 0.1)So , L2 = 0.005 0.1
Miss in L2 = 0.05
- An instruction pipeline has five stages where each stage takes 2 nanoseconds and all instructions use all five stages. Branch instructions are not overlapped, i.e., the instruction after the branch is not fetched till the branch instruction is completed. Under ideal conditions.
(a) Calculate the average instruction execution time assuming that 20% of all instruction executed are branch instructions. Ignore the fact that some branch instructions may be conditional.
(b) If a branch instruction is a conditional branch instruction, the branch need not be taken. If the branch is not taken, the following instructions can be overlapped. When 80% of all branch instructions are conditional branch instructions, and 50% of the conditional branch instructions are such that the branch is taken, calculate the average instruction time.
-
View Hint View Answer Discuss in Forum
(a) 3.6 nano seconds (b) 2.96 nano seconds
Correct Option: C
(a) 3.6 nano seconds (b) 2.96 nano seconds
- The performance of a pipelined processor suffers if
-
View Hint View Answer Discuss in Forum
Pipelining is a method to execute a program breaking it in several independent sequence of stages. In that case pipeline stages can't have different delays, no dependency among consecutive instructions & sharing of hardware resources shouldn't be there. So option (d) is true.
Correct Option: D
Pipelining is a method to execute a program breaking it in several independent sequence of stages. In that case pipeline stages can't have different delays, no dependency among consecutive instructions & sharing of hardware resources shouldn't be there. So option (d) is true.

