Computer organization and architecture miscellaneous
- Consider a non-pipelined processor with a clock rate of 2.5 gigahertz and average cycles per instruction of four. The same processor is upgraded to a pipelined processor with five stages; but due to the internal pipelined delay, the clock speed is reduced to 2 gigahertz. Assume that there are no stalls in the pipeline. The speed up achieved in this pipelined processor is _____.
-
View Hint View Answer Discuss in Forum
Speed up = Old execution time New execution time = CPIold CFold CPInew CFnew
(where CF is clock frequency and CPI is cycles per intruction. So, CPI / CF gives time per instruction)= 4 2.5 = 3.2 1 2
Without pipelining an instruction was taking 4 cycles. After pipelining to 5 stayes we need to see the maximum clock cycle a staye can take and this will be the CPI assuning no stalls.Correct Option: D
Speed up = Old execution time New execution time = CPIold CFold CPInew CFnew
(where CF is clock frequency and CPI is cycles per intruction. So, CPI / CF gives time per instruction)= 4 2.5 = 3.2 1 2
Without pipelining an instruction was taking 4 cycles. After pipelining to 5 stayes we need to see the maximum clock cycle a staye can take and this will be the CPI assuning no stalls.
- Consider a 3GHz (Gigahertz) processor with a threestage pipeline and stage latencies τ1, τ2, and τ3 such that τ1 = 3 τ2 / 4 = 2τ3. If the longest pipeline stage is split into two pipeline stages of equal latency, the new frequency is_______ GHz, ignoring delays in the pipeline registers.
-
View Hint View Answer Discuss in Forum
Pipeline
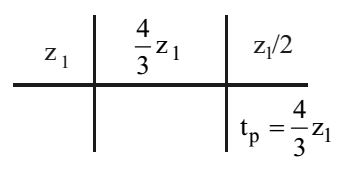
New Pipeline
Correct Option: B
Pipeline
New Pipeline
- Suppose the functions F and G can be computed in 5 and 3 nanoseconds by functional units UF and UG, respectively. Given two instances of UF and two instances of UG, it is required to implement the computation F(G(Xi)) for 1 ≤ i ≤ 10. Ignoring all other delays, the minimum time required to complete this computation is _______ nanoseconds.
-
View Hint View Answer Discuss in Forum
This concept is used in pipelining. The important thing here is UF as it takes 5 ns while UG takes 3 ns only. One have to do 10 such calculations. According to question, we have 2 instances of UF and UG respectively. So, UF can be done in 50 / 2 = 25 nano seconds. For the start, UF needs to wait for UG output for 3 ns and rest all are pipelined and hence no more wait. Therefore, the answer will be :
3 + 25 = 28 nsCorrect Option: A
This concept is used in pipelining. The important thing here is UF as it takes 5 ns while UG takes 3 ns only. One have to do 10 such calculations. According to question, we have 2 instances of UF and UG respectively. So, UF can be done in 50 / 2 = 25 nano seconds. For the start, UF needs to wait for UG output for 3 ns and rest all are pipelined and hence no more wait. Therefore, the answer will be :
3 + 25 = 28 ns
- The stage delays in a 4-stage pipeline are 800, 500, 400 and 300 picoseconds. The first stage (with delay 800 picoseconds) is replaced with a functionally equivalent design involving two stages with respective delays 600 and 350 picoseconds. The throughput increase of the pipeline is __________ percent.
-
View Hint View Answer Discuss in Forum
Old design tp = 800
New design tp = 600Throughput = 800 - 600 × 100% = 33.33% 600 Correct Option: C
Old design tp = 800
New design tp = 600Throughput = 800 - 600 × 100% = 33.33% 600
- Instruction execution in a processor is divided into 5 stages. Instruction Fetch (IF). Instruction Decode (ID). Operand Fetch (OF). Execute (EX), and Write Back (WB). These stages take 5, 4, 20, 10, and 3 nanoseconds (us) respectively. A pipelined implementation of the processor requires buffering between each pair of consecutive stages with a delay of 2 ns. Two pipelined implementations of the processor are contemplated :
(i) a naive pipeline implementation (NP) with 5 stages and
(ii) an efficient pipeline (EP) where the OF stage is divided into stages OF1 and OF2 with execution times of 12 ns and 8 ns respectively. The speedup (correct to two decimal places) achieved by EP over NP in executing 20 independent instructions with no hazards is _______ .
-
View Hint View Answer Discuss in Forum
Given for Native pipeline, the number of stages (k) = 5.
tP1 = Max(Stage delay + buffer delay)
Buffer delay = 2nS
Stage delay = 5, 4, 20, 10, 3
So
tP1 = Max((5 + 2), (4 + 2), (20 + 2), (10 + 2), (3 + 2))
= Max (7, 6, 22, 12, 5)
Maximum value is 22.tP1
Number of instruction (n) = 20
So, execution time for native pipeline (NP).
Then,
Execution time (TNP) = (k + n – 1) tP1
= (5 + 20 – 1) 22 n sec.
TNP = 528 n sec.
Now, for efficient pipeline (TEP), the number. of stages (k = 6), n = 20, tP2 = ? tP2 = Max (Stage delay + Buffer delay)
= (12 nS + 2 nS) = 14 ns.
So, TEP = (k + n – 1) tP2
= (6 + 20 – 1) * 14 = 350 n sec.Speed up (S) = TNP = 528 = 1.508 TEP 350 Correct Option: B
Given for Native pipeline, the number of stages (k) = 5.
tP1 = Max(Stage delay + buffer delay)
Buffer delay = 2nS
Stage delay = 5, 4, 20, 10, 3
So
tP1 = Max((5 + 2), (4 + 2), (20 + 2), (10 + 2), (3 + 2))
= Max (7, 6, 22, 12, 5)
Maximum value is 22.tP1
Number of instruction (n) = 20
So, execution time for native pipeline (NP).
Then,
Execution time (TNP) = (k + n – 1) tP1
= (5 + 20 – 1) 22 n sec.
TNP = 528 n sec.
Now, for efficient pipeline (TEP), the number. of stages (k = 6), n = 20, tP2 = ? tP2 = Max (Stage delay + Buffer delay)
= (12 nS + 2 nS) = 14 ns.
So, TEP = (k + n – 1) tP2
= (6 + 20 – 1) * 14 = 350 n sec.Speed up (S) = TNP = 528 = 1.508 TEP 350

