Computer organization and architecture miscellaneous
- A 5 stage pipelined CPU has the following sequence of stages
IF : Instruction fetch from instruction memory
RD : Instruction decode and register read
EX: Execute: ALU operations for data and address computation
MA : Data memory access : for write access, the register read at RD stage is used
WB : Register write back
Consider the following sequence of instructions :
I1 : L R0 loc 1; R0 < = M [loc1]
I2 : A R0 ; R0 ; R0 < = R0 + R0
I3 : S R2; R0 ; R2 < = R2 – R0
Let each state takes on clock cycle.
What is the number of clock cycles taken to complete the above sequence of instructions starting from the fetch of I1 ?
-
View Hint View Answer Discuss in Forum
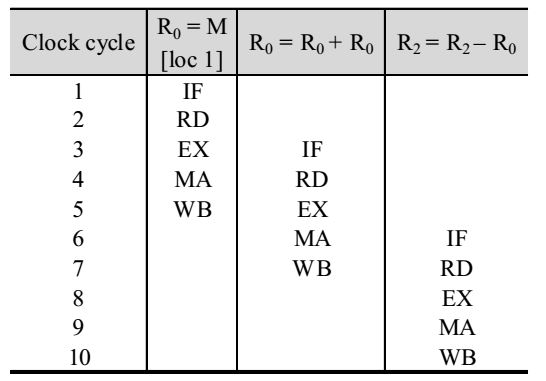
Thus, total number of clock cycles required = 10Correct Option: A
Thus, total number of clock cycles required = 10
- A CPU has a five-stage pipeline and runs at 1 GHz frequency. Instruction fetch happens in the first stage of the pipeline. A conditional branch instruction computes the target addresses and evaluates the condition in the third stage of the pipeline. The processor stop fetching new instructions following a conditional branch until the branch outcome is known. A program executes 109 instructions out of which 20% are conditional branches. If each instruction takes one cycle to complete on average, the total execution time of the program is
-
View Hint View Answer Discuss in Forum
In the 3rd stage of pipeline, there will be 2 shall cycles.
Total number of instructions = 109, 20% out of 109 are conditional branches. Therefore, cycle penalty = 0.2 * 2 * 109 = 4 * 108.
Clock speed is 1GHz and each instruction on average takes 1 cycle. soTotal execution time = 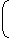
109 
+ 4* 108 109 109
= 1 + (0.4) = 1.4 secCorrect Option: C
In the 3rd stage of pipeline, there will be 2 shall cycles.
Total number of instructions = 109, 20% out of 109 are conditional branches. Therefore, cycle penalty = 0.2 * 2 * 109 = 4 * 108.
Clock speed is 1GHz and each instruction on average takes 1 cycle. soTotal execution time = 109 + 4* 108 109 109
= 1 + (0.4) = 1.4 sec
- Consider a pipelined processor with the following four stages
IF : Instruction Fetch
ID : Instruction Decode and Operand Fetch
EX : Execute
WB : Write Black
The IF, ID and WB stages take 1 clock cycle each to complete the operation.
⚈ The number of clock cycle for the EX stage depends on the instruction. the ADD and SUB instructions need 1 clock cycle and the MUL instruction needs 3 clock cycles in the EX stage. Operand forwarding is used in the pipelined processor. What is the number of clock cycles taken to complete the following sequence of instructions:
-
View Hint View Answer Discuss in Forum
As given the pipelined processor has four stages i.e., IF, ID, EX, WB, And we know that number of clock cycles required to ADD and SUB instructions is 1 and by MUL instructions are 3.
In the pipelined processor while one instruction is fetched, the other is either being decoded or executed or some action is being performed. Thus, the number of cycles required by the given set of instructions can be obtained from the following diagram.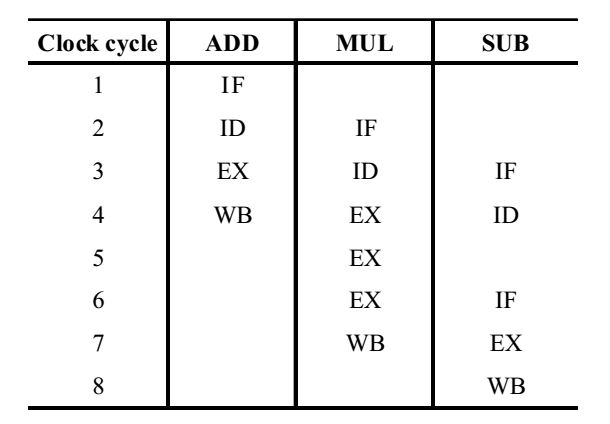
Thus, total number of clock cycles required are 8.Correct Option: B
As given the pipelined processor has four stages i.e., IF, ID, EX, WB, And we know that number of clock cycles required to ADD and SUB instructions is 1 and by MUL instructions are 3.
In the pipelined processor while one instruction is fetched, the other is either being decoded or executed or some action is being performed. Thus, the number of cycles required by the given set of instructions can be obtained from the following diagram.
Thus, total number of clock cycles required are 8.
- Which of the following are not true in a pipelined processor?
1. Bypassing can handle all RAW hazards.
2. Register renaming can eliminate all register carried WAR hazards.
3. Control hazard penalties can be eliminated by dynamic branch prediction.
-
View Hint View Answer Discuss in Forum
I. False, Bypassing can’t handle all raw hazard, consider when any instruction depends on the result of LOAD instruction, now load updates register value at Memory Access stage (MA). So data will not be available directly on Execute stage. II. True, register renaming can eliminate all WAR Hazard. III. False, it cannot completely, through it can reduce control Hazard Penalties.
Correct Option: B
I. False, Bypassing can’t handle all raw hazard, consider when any instruction depends on the result of LOAD instruction, now load updates register value at Memory Access stage (MA). So data will not be available directly on Execute stage. II. True, register renaming can eliminate all WAR Hazard. III. False, it cannot completely, through it can reduce control Hazard Penalties.
- The following code is to run on a pipelined processor with one branch delay slot :
l1 : ADD R2 < R7 + R8
l2 : SUB R4 ← R5 – R6
l3 : ADD R1 ← R2 + R3
l4 : STORE Memory [R4] ← R1
BRANCH to Label if R1 = 0
Which of the instructions I1, I2, I3 or I4 can legitimately occupy the delay slot without any other program modification?
-
View Hint View Answer Discuss in Forum
I4, the store instruction can be moved below the conditional branch instruction. whether the branch is taken or not, STORE will be executed as the next instruction after conditional branch instruction, due to delayed branching. Here, I3 is not the answer because the branch conditional variable R1 is dependent on it. same for I1, similarly, I4 has a dependency on I2 and hence I2 must be executed before I 4
Correct Option: D
I4, the store instruction can be moved below the conditional branch instruction. whether the branch is taken or not, STORE will be executed as the next instruction after conditional branch instruction, due to delayed branching. Here, I3 is not the answer because the branch conditional variable R1 is dependent on it. same for I1, similarly, I4 has a dependency on I2 and hence I2 must be executed before I 4

